8. Regression and Classification¶
This chapter introduces linear models, a keystone of data analysis, and Scikit Learn, a software suite written in Python that includes a vast array of machine learning tools extending far beyond linear models. Scikit has steadily grown since its inception in 2007 and its first release in 2010, building up a large, enthusiastic community of users in academia, government, and business.
There are a number of reason for this success. The implementations are efficient (within the limits of Python) and in step with the state of the art of machine learning and data analysis. The tools have a consistent, easy-to-use interface. Learning how to use linear models gives you instant access to a variety of other approaches. The breadth of coverage is astonishing, the documentation is extensive and always supplies well-chosen examples. The well-referenced tutorials, while terse, do an excellent job of explaining the motivations and the main ideas for the software.
In this chapter, we focus on one sliver of Scikit Learn, packages implementing linear models for regression and classification; we will then turn around and take what we have learned about linear models and apply it in the realm of text classification.
We are going start with regression analysis, the task of modeling the behavior of one variable, the dependent variable, using the values of any number of others, the predictors. The idea is to discover a mathematical relationship between the predictors and the dependent variable that comes as close as possible to predicting the value of the dependent variable. When it’s possible to do it well, regression can be a very powerful tool for understanding data because it answers questions about which factors contribute the most to changes in the dependent variable, and that opens the door to explanations and data driven decision-making.
The regression example will help us understand the mathematical definition of linear models. We will very quickly proceed from using scikit learn to build simple linear regression models to generalized linear regression models like polynomial models and logistic regression. The goal in this chapter is not provide a deep, mathematical understanding. That’s the job of a statistics or machine learning text. The goal here is simply to introduce you to the tools, provide with an intuition of what they do for you, and leverage your knowledge of Python to put them to use on real data.
After regression we will move on to the closely related topic of machine learning classifiers, programs that are trained on labeled data to learn how to attach labels to previously unseen data. After a few toy examples to illustrate the basic, we will on to text claissification. Text classifcation is a key area in natural language processing. Sorting texts into classes enables us to group them and bin them and turns a raw sequence of with very hard to predict proerties into something we can use. Applications include spam and bot detection, sentiment analysis, and customer experience management.
Text classification appears to involve some amount of meaning analysis. The problem with any kind text analysis is that there are too many words. Bill Paisley’s description of the problem is now nearly a half century old, but holds up pretty well:
Thanks to paper and ink, words are a durable human artifact … words form the running records of civilization and also the episodic record of individual experience. Words are rich data for all social research, from psychiatry to cultural anthropology.
Unfortunately, there are always too many words. Words produced in minutes may justify hours of analysis. A set of psychiatric interviews, or editorials in Pravda, or a collection of folktales can occupy (and have occupied) researchers for months.
Thus, what text analysts faced with large quantities of text have historically sought to do is to filter it, running it through a strainer that captures the major strands of content, or to crop it, mining it for specific bits of content. Paisley’s complaint comes at the beginning of a review of the Harvard General Inquirer system, a prime example of the filtering approach, which seeks to boil a text down to core set of high content or high significance words. But computational tools have come a long way since Paisley wrote these words, both in sophistication and in raw computational power: Machine learning now offers a third alternative, representing text as points in a high-dimensional space in which we can draw class boundaries that take into account the contributions of all words.
Contents
- 8.1. Simple regression: Don’t think too hard!
- 8.2. Regression Examples
- 8.2.1. Loading data
- 8.2.2. Make a linear regression model
- 8.2.3. Doing it by hand
- 8.2.4. The scitkit_learn (aka sklearn) linear regression module
- 8.2.5. Other models
- 8.2.6. Evaluating Regression models (
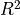 vs MSE)
vs MSE) - 8.2.7. Choosing features
- 8.2.8. Ridge learning (regularization)
- 8.2.9. Summary thus far
- 8.2.10. Non-linear example: K Nearest Neighbor Regression
- 8.2.11. Adding more variables to the pipeline
- 8.3. Classification Tutorial
- 8.3.1. The data
- 8.3.2. Plotting attributes
- 8.3.3. Plotting 2D Projections of the data
- 8.3.4. Linear separation
- 8.3.5. Relationship to regression
- 8.3.6. Linear classifier results
- 8.3.7. Evaluating a classifier: General ideas
- 8.3.8. Training/test split
- 8.3.9. PCA as classifier
- 8.3.10. Classification example: Recognizing adjectives
- 8.3.11. Accuracy, Precision, and Recall
- 8.3.12. Precision-Recall Trade-off: Adjective Example
- 8.3.13. F1-Score: A single number combining precision and recall
- 8.3.14. Appendix C: AUC score
- 8.3.15. Appendix D: An evaluation experiment
- 8.3.16. Appendix E: Working with confusion matrixes
- 8.3.17. Appendix F: Using different types of Classifiers
- 8.4. Text Classification: Insults with Naive Bayes
- 8.4.1. Loading and preparing the data
- 8.4.2. Analyzing insults with Naive Bayes: sklearn
- 8.4.3. Explaining TFIDF
- 8.4.4. Working through the insult data
- 8.4.5. Training
- 8.4.6. Summarizing everything up till now
- 8.4.7. Basic train and test loop
- 8.4.8. Refined train and test loop
- 8.4.9. Most important features
- 8.4.10. Running the classifier on a list of sentences