Syllables may be broken up into onset, nucleus, and coda.
The nucleus is the vowellike part. Every syllable has a nucleus. Onsets and codas are optional:
| Rhyme | ||||
|---|---|---|---|---|
| Onset | Nucleus | Coda | Note | Spelling |
| k | æ | n | all | can |
| s | i | no coda | see | |
| i | t | no onset | eat | |
| spr | aj | t | all | sprite |
| skr | æ | t∫ | all | scratch |
| spr | i | no coda | spree | |
| æ | nts | no onset | ants | |
The nucleus and coda, as shown, are often spoken of as a unit called the rhyme.
Given this picture, syllabification is not trivial. Which syllabification is correct for extreme?
- [e'kstrim]
- [ek'strim]
- [eks'trim]
- [ekst'rim]
- [ekstr'im]
| Bilabial | p b m n w |
| Labiodental | f v |
| Interdental | ð th |
| Alveolar | t d s z |
| Alveopalatal | ∫ zh t∫ dzh |
| Palatal | j |
| Velar | k g ng w |
| Glottal | h ? |
Manners are themselves divided up into two major classes: Obstruents and sonorants. The obstruents are the stops, the fricatives, and the affricates. The sonorants are the vowels, liquids, glides, and nasals. Attention: The following table only shows consonants so it does not include ALL the sonorants.
| Obstruents | Stops | p b t d k g ? |
| Fricatives | f v th ð s z ∫ zh | |
| Affricates | t∫ dzh | |
| Sonorants | Nasals | m n ng |
| Liquids | r l | |
| Glides | j w |
Voicing: All English sonorants are voiced, except that [w] may be voiceless. Obstruents come in voiced/voiceless pairs except for [h] and [?].
| Voiceless | p | t | k | f | th | ∫ | t∫ | h | ? |
| Voiced | b | d | g | v | ð | zh | dzh |
features
Our chapter introduces a large number of features and classifies all the sounds of English according to these features (Tables 3.25, 3.26, pp. 82, 83)
Here are the features I want you to know:
| Voice | All sonorants are voiced in English except that in some dialects there is a voiceless [w] (transcribed as an upside down [w]). All obstruents come in voiced/voiceless pairs except for [h] and [?] which are |
| Sonorant | All vowels, glides, liquids, and nasals are +Sonorant. All obstruents are -Sonorant. |
| Consonantal | All vowels are -Consonantal. However contrary to your intuitions, glides and glottals are also -Consonantal. The rest of the consonants are +Consonantal. |
| Syllabic | The intuition of +Syllabic is that the sound can occur as syllable nucleus. Vowels are always +Syllabic. Liquids and nasal CAN be either + or - Syllabic. When they are syllable nuclei (huddle, button) they are +Syllabic. |
| Continuant | The primary function of this feature is to distinguish fricatives, +Continuant, from other obstruents (stops and affricates), -Continuant. All sonorants except for nasals are -Continuant (and don't worry about nasals). |
Attention: The feature +/- consonantal does not QUITE mean what you think.
| [-sonorant] | ||
| [-voice] | [+voice] | |
|
p t k |
b d g |
[-continuant] |
|
f s ∫ |
v z zh |
[+continuant] |
Some natural classes
|
-sonorant |
-sonorant -continuant |
-sonorant -continuant -voice |
|
p t k b d g ? f s ∫ v z zh |
p t k b d g ? |
p t k |
| Obstruents | Stops |
Voiceless Stops |
Another example:
|
-sonorant |
-sonorant +continuant |
-sonorant +continuant -voice |
|
p t k b d g ? f s ∫ v z zh |
f s ∫ v z zh |
f s ∫ |
| Obstruents | Fricatives |
Voiceless Fricatives |
In general the feature system is set up so as to make the specification of NATURAL sound classes easy. There are place features (which we are not studying) which make the selection of all the sounds at one place of articulation easy. For example, selecting EXACTLY the set of sounds k,ng, g could be done with the following specification (which uses the place of articulation feature Dorsal):
- Continuant º DorsalPretty easy.
Restricting this further to k,g, also easy:
- Sonorant - Continuant º Dorsal
Some sound classes are NOT natural. For example restricting the first set to the set k, ng (excluding g) would be very hard.
- Voice + Voice - Sonorant + Sonorant - Continuant OR - Continuant º Dorsal º Dorsal
All languages except sign languages use sequences of phones to make words.
No languages allow sounds to combine freely. That is, there are always constraints on what phones any particular phone can precede and follow. These constraints are called phonotactic constraints.
- The English morpheme re must always precede the stem it is attached to. It can never follow the stem.
- When the English morpheme ity
and the English plural morpheme s occur
together, ity must always precede the
plural. It can never follow:
-
profane + ity + s = profanities
* profane + s + ity = profanesity
Syntactic constraints are constraints on the arrangements of words. Phonotactic constraints are constraints on the arrangements of phones.
What kind of constraints are the following?
- The sum total of all the phonotactic constraints of a language is called its phonotactics.
- The sum total of all the morphotactic constraints of a language is called its morphotactics.
- The sum total of all the syntactic constraints of a language is called its syntax.
Zeroing on phonotactics:
- In any syllable-internal sequence
of a nasal and a stop, the nasal and the stop
must have the same place of articulation:
Actual Impossible Possible hand *hamd hant taunt *taumt taund punk *pumk pung Is henpecked a counterexample?
- In any 2-consonant onset,
the second consonant must be a sonorant.
Actual Impossible please *ptease proud *psoud pure[pjur] *pshure twin *tdin trust *tpust queen *ksean clean *cshean cream *cteam - In any 3-consonant cluster in an onset, the first consonant must be [s]: splash, strong, spew [s p j u], extreme [∈ k 's t r ij m].
- In any 3-consonant cluster in an onset,
the second consonant must be a voiceless stop [p,t,k]:
splash, strong, spew [s p j u], extreme [∈ k 's t r ij m].
Thus although we have smooth [s m u th] and museum [m j u z i uh m], we have no words beginning [s m j u...]
Phonotactic constraints are highly language-particular. Japanese has NO onset clusters. It basically has Consonant-Vowel syllables(although it allows nasals as codas). So all of the complex onsets described above are forbidden. This is very common. We call such a language a CV language.
On the other hand we have Polish:
| co | [t s o] | what |
| kto | [k t o] | who |
| ptak | [p t a k] | bird |
| przez | [p ∫ ∈ s ] | by/through |
| ksiazka | [k ∫ o n ∫ k a] | book |
| zgniecic | [z g n j ∈ t∫ i t∫] | crush |
| grzmot | [g zh m ao t] | thunderbolt |
Predictability
Phonology is the study of the sound patterns of a language. Phonotactics is part of phonology.
Another part is the study of predictable sound changes.
We now discuss predictable phonological changes
In most cases phones are not predictable. The fact the d is the first sound in the English word for dog is not predictable.
But sometimes the occurrence of some phones is quite predictable. The ability to master these predictable patterns is part of a native speaker's mastery of a language (and the failure to master them part of what gives non-native speakers an accent).
Thus it is part of what a linguist calls the grammar of the language. More on this the grammar section below.
Epenthesis
There are times when sounds are inserted in a language in order to enforce phonotactic constraints.
Consider problem 15, p. 107.
This kind of process, in which one sound is inserted in a predictable way, is called epenthesis. Thus the inserted glides in Tamil are epenthetic glides.
For many dialects of English there are epenthetic glides as well. Consider the transcriptions of the following words:
- boat: [b ow t]
- bait: [b ej t]
- hold: [h ow l d]
- hate: [h ej t]
- post: [p ow s t]
- pale, pail: [p ej l]
The glide is predictable. It is part of a pattern in English.
We do not want to list it in the dictionary pronunciation for each word. We want a rule to take care of this.
Rule: Insert a [w] after [o] and a [j] after [e]
∅ -> w / o _
∅ -> j / e _
Grammar
A grammar is a formal specification of what a native speaker of a language knows. Part of a job of a grammar is to capture the predictable patterns. The other part is to capture what's unpredictable.
Thus, a grammar consists of two basic components:
- Lexicon: A dictionary consisting of basic forms (words/morphemes)
- Rules
- Tactical rules: Phonotactics/morphotactics/syntax
- Redundancy rules: Rules adding features which are completely predictable
The glide epenthesis rules for Tamil and English were redundancy rules. They added predictable features, namely glides, to words. Such features are said to be derived, because they are inferred or proven by general principles about the language.
Thus such features are NOT found in the lexicon.
Derivation of boat Lexicon
. . .
/ b o t /
. . .Phonemic
Representation⇓
Rules
. . .
∅ -> w / o _
. . .
Computation ⇓
Surface [b ow t] Phonetic
RepresentationOur focus in this chapter is redundancy rules. When we say rule, we almost always mean redundancy rules unless we say otherwise.
Rules take the following form
A -> B / C _ D
This means B is a predictable realization of A in the environment C _ D (following C and preceding D). Sometimes it is enough to specify what follows or what precedes and we see only D or only C. In the case of English glide epenthesis, it was enough to specify what preceded:∅ -> w / o _
Vowel
Length
Another predictable feature of English words is vowel length.
Consider Table 3.32, p. 91. It shows that English vowels are lengthened before certain sounds.
What is the pattern distinguishing Column A from Column B?
| A | B | ||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Pairs
Vowel length is not predictable in every language.
Consider Table 3.4, p.62, which show that vowel length is distinctive in Japanese and Finnish.
| Japanese (dx is a flap) | ||||||||||
|
||||||||||
| Finnish | ||||||||||
|
The pairs of words in these tables such as tuli and tu:li in Finnish are called minimal pairs. They are minimal in that they differ in the minimal way, one sound. The fact that two forms differ in one sound and mean different things in a language shows that the sound can make meaningful distinctions in that language. We say the sounds are distinctive.
Vowel length is distinctive in Finnish and Japanese.
Vowel length is NOT distinctive in English. Therefore there exist NO pairs of words like [t u l i] and [t u: l i] in English, words which mean different things and differ ONLY in the length of a particular vowel.
versus
Predictability
The following principle is the most important concept of the chapter.
Distinctiveness and predictability are mutually exclusive.
If a feature is phonetically predictable like English vowel length, then it cannot function to make meaningful distinctions. It appears only in the company of something else that is really making the meaningful distinction.
Notice that you canNOT have minimal pairs with English vowel length: Long vowels show up only preceding voiced obstruents. So any word with a lengthened vowel will have at least TWO differences from a word without one: the vowel length and the voicing of the final obstruent.
So we can have:
| bat | [b æ t] | |
| bad | [b æ: d] |
Allophones
We call the phones listed in the lexicon phonemes. We write these forms in slashes: /æ/.
/æ/ is a listed in the dictionary. It is consequence of the rule we just formulated that it can sometimes be realized as [æ:]. When that happens is completely predictable.
It is also a consequence of the rule that [æ] can sometimes be realized just as plain old [æ]. This is also completely predictable (/æ/ is realized as [æ] whenever /æ/ is not followed by a voiced obstruent in the same syllable).
The following tree pictures the situation:
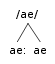
Aspiration
Consider Table 3.30, p. 90, which shows the distribution of aspirated and unaspirated stops in English.
| A | B | C | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|
Pairs II
Voiceless aspirated stops are allophones of voiceless unaspirated stops in English.
Thus, aspiration is NOT distinctive in English. But there are languages in which aspiration is distinctive.
Consider the data in Khmer (Cambodia) in Table 3.14, p. 69.
| [p ao: ng] | to wish | [ph ao: ng] | also |
| [t ao p] | to support | [th ao p] | be suffocated |
| [k a t] | to cut | [kh o t] | to polish |
In particular, both occur in syllable initial position, the environment that predicts aspiration in English. The words on the left are NOT possible words of English.
Problems:
Complementary
Distribution
It is a consequence of the predictability of allophones that they never occur in the same environments.
If an unaspirated stop ever occurred in syllable initial position our rule would just be plain wrong.
Counterexample to aspiration rule: [p I n]
Similarly if a [ph] occurred after an [s]:
[s ph I n]this would show that our description was wrong.
The environments of allophones must be mutually exclusive.
We have a general term for the situation that arises whenever two sounds occur in mutually exclusive environments. We say they are in complementary distribution.
Allophones of the same phoneme must always be in complementary distribution.
Are [æ] and [æ:] in complementary distribution? Yes. [æ:] occurs whenever /æ/ is followed by a voiced obstruent in the same syllable. [æ] occurs everywhere else.
Whenever you claim that two phones are allophones of the same phoneme you must justify this this claim. The first step to justifying this claim is to show that they occur in mutually exclusive environments.
Thus when you state the environments of two allophones be sure to do so in a way that makes them mutually exclusive. Simple descriptions make this easier.
Example data (k vs. x)
| x i n |
| t k æ |
| r k u |
| [x] occurs before [i]. [k] occurs after [t] and [r]. | Bad. This is true but it is not a description
which justifies a claim of allophony because the
environments are NOT mutually exclusive. Which
phone would arise in the following environment?
t _ i |
| [x] occurs before [i]. [k] occurs before [æ] and [u]. | OK. Could be simpler. But no way they occur in the same environment. |
| [k] occurs before [æ] and [u]. [x] occurs elsewhere. | Better. Elsewhere conditions guarantee mutual exclusivity and are simpler. But there is a better answer. |
| [x] occurs before [i]. [k] occurs everywhere else | Good. Simpler than the previous answer. The sound that occurs in the most restrictive environment comes first. The other phone is the "elsewhere" phone. |
Examples of good elsewhere phones:
- [p]. Occurs at the end of syllables and in the onset when not the first sound. [ph] has the more restrictive distribution (syllable initial). State the distribution of [ph]. Say [p] occurs everywhere else.
- [æ]. Occurs whenever there isnt a voiced obstruent following in the same syllable. But avoid such negative statements. Say [æ:] occurs whenever there is a voiced obstruent following in the same syllable. [æ] occurs elsewhere.
Vowel raising
Consider the data in Table 3.9, p. 66.
liquids
Consider the data in Table 3.5, p. 62.
Allophony
Problems