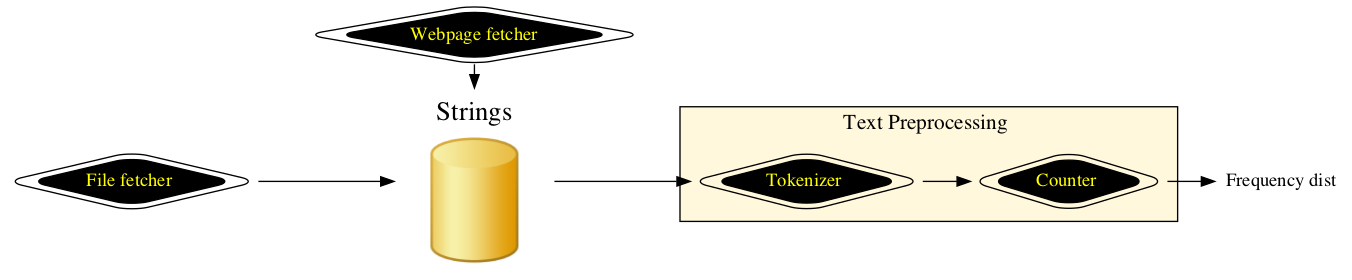
7.5. Putting it all together: Text preprocessing¶
There are many different kinds of analytical tasks one might undertake with text, but there are certain preliminary steps shared by these tasks. We will call these text preprocessing.
The following code examples put a lot of the concepts we have been using together and introduce some routine tasks of text preprocessing:
1import nltk
2from collections import Counter
3
4def word_freqs_file(filename):
5 with open(filename,'r') as fh:
6 text = fh.read()
7 # Tokenize the resulting string using English orthography conventions
8 # and return a Counter for the word freqs
9 return Counter(nltk.word_tokenize(text))
Covering come of the key steps:
Line 1: We import a new module
nltk, short for Natural Language Tool Kit. This module contains a host of tools for processing text and language.Line 2: We import the
Counterclass, discussed in Dictionaries as a way of recording word counts.Lines 4-9. We define a function
word_freqs_filewhich opens up and reads a file and returns the word frequencies for that file.Lines 5,6: Open the file and read it in as one long string with the
readmethod on file handles storing it in the variabletext.Line 9: This single calls the
nltkword_tokenize. This tokenizer does a much better job accurately breaking the stringtextinto words thantext.split()would. Alternatively, We might plug in a regular expression pattern defining “possible word” (which would exclude all punctuation marks, for example), and use re.findall. Whether you usenltk.word_tokenizeor regular expressions, the result of tokenization is a list of words. It is this list we pass to theCountercreation function to get the word frequencies for the file.
The following variant works on web pages instead
of files. It uses an nltk program
called clean_url to download the web page as a text
string; what is important to know here
is what clean_url requires
as input (a web address, or URL) and what it returns
(a long string containing all the text content of the web page,
with the HTML formatting markup stripped away):
1import nltk
2from collections import Counter
3
4def word_freqs_webpage(url):
5 ## Download webpge and strip away all html
6 text = nltk.clean_url(url)
7 # Tokenize the resulting string using English orthography conventions
8 # Return Counter for the word freqs
9 return Counter(nltk.word_tokenize(text))
Notice that the two functions word_freqs_file and
word_freqs_webpage share a line of code, line 9 above.
This suggests that the line could be bundled up into
a reusable function. The right organization for
these lines of code is something like:
1import nltk
2from collections import Counter
3
4def word_freqs_webpage(url):
5 ## Download webpge and strip away all html
6 ## return freq_dist
7 return get_freq_dist(nltk.clean_url(url))
8
9def word_freqs_file(filename):
10 with open(filename,'r') as fh:
11 return get_freq_dist(fh.read())
12
13def get_freq_dist (text):
14 # Tokenize the resulting string using English orthography conventions
15 # And return the counts
16 return Counter(nltk.word_tokenize(text))
We have abstracted freq_dist out as a function of its which
takes in a text string and returns a frequency distribution.
This is a useful piece of abstraction because
there are many different kinds of sources of a text
string, from the web to files to user input to Graphical
User interface, and this function does not need any information
about where the string came from to operate correctly.
7.5.1. Summary¶
Text needs to be properly tokenized if we are going to do some kind of statistics or modeling that depends on the words in it. The
nltkmodule provides a good text tokenizer. We can also use regular expressions for this task,NLTK also provides tools for downloading web pages and converting them to text, stripping away HTML. There are some donwsides to doing things this way, to be covered when we look at web scraping in more detail in Chapter web_intro.
Text processing breaks down into certain natural reusuable steps and good reusable code should provide fit into a natural text processing pipeline. In this section we looked at the following steps.