3.3. Python types¶
In this section. we discuss two basic kinds of objects in Python, numbers and strings. There are lots of other kinds of objects in Python, but these are the two most important for the kinds of problems discussed in this course.
In addition, they provide a good starting point for understanding some of the other Python types.
3.3.1. Numbers¶
First, as our first Python session showed, there are numbers:
>>> X = 3
Python actually has several different number types. In many simple scripts, Python programmers do not actually have to think about the different kinds of numbers (this is not true in every programming language!). Nevertheless, it is helpful to understand the basic concept, and since we are going to have to understand how different data types work, it helps to understand how the simplest kinds of type distinctions work, and some of the motivations behind them.
Figure Python number types shows the Python type tree for numbers.
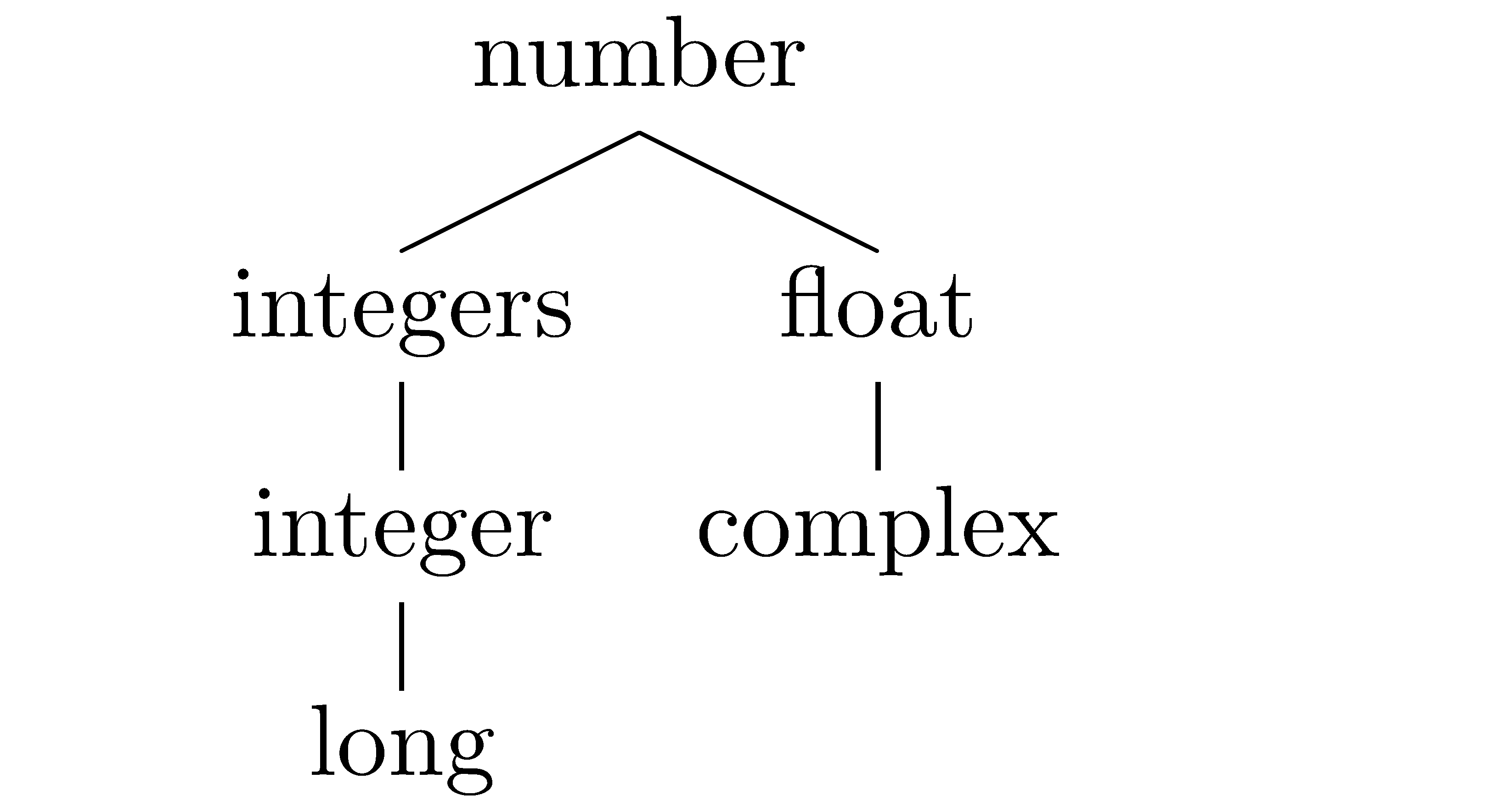
Python number types¶
Let’s start with the distinction between
integers and floats. For most purposes, you can
simply think of this as a distinction between the kinds
of values you want to represent. For values that are
exactly equal to integers (…, -2, -1, 0, 1, 2, …),
you use integers (Python type name int); for values that come in between, you use
floats:
>>> type(1)
int
>>> type(1.2)
float
>>> X = 1
>>> type(X)
<type 'int'>
>>> X = 1.2
>>> type(X)
<type 'float'>
Now the real question is why bother to have this distinction
at all? Why not just have a number type and leave it at that?
The answer in part is space. It takes a lot of information to represent
values between 1 and 2 exactly. In fact, for many values
that come up in mathematics (The value of 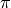 , for example),
it would necessarily take an infinite amount of space.
In a decimal representation, fractions like
, for example),
it would necessarily take an infinite amount of space.
In a decimal representation, fractions like  are infinitely
repeating decimals, and would also take an infinite of
space to represent exactly. Since numbers are represented as binary fractions
in computer memory, a different set of fractions comes out as infinitely
repeating in computer memory (.1, for example) [1] .
are infinitely
repeating decimals, and would also take an infinite of
space to represent exactly. Since numbers are represented as binary fractions
in computer memory, a different set of fractions comes out as infinitely
repeating in computer memory (.1, for example) [1] .
So what we do instead is set aside a standard amount of space for each floating point number we want to use, in fact quite a lot of space — to allow for satisfactory precision in extended calculations. On the other hand, sometimes we don’t want to use numbers for extended mathematical calculations of arbitrary precision. Sometimes we just want to use them for counting. So when I use a particular variable to store the number of times I see the word ricochet, I know that no matter how much data I’ve got, the number of times the word occurs can still be represented by an integer. So for storing an integer we set aside another smaller amount of space, and just as there are floats I cant represent in the given amount of space, so there are also integers (big ones) I can’t represent in the agreed-upon amount of space. Now if I really need more space, there is another BIGGER data type I can use for REALLY big integers (say I am counting subatomic events), called a long (or long integer), and that too has its limits. When the absolute value of numbers gets too big to represent in the amount of memory available, that’s called overflow.
Finally, there is a distinct number type for complex numbers, which are really numbers with two number components:
>>> X = 3j+2
>>> type(X)
<type 'complex'>
And these come up less in Social Science settings, so we’ll pass over them quickly.
In sum, each of the number data types has its specific purposes, and its specific limits. In general each number type has its maximum and minimum value; floats have maximum precision values, which means, for example, that certain numbers are too close to 0 to represent. This problem is called underflow.
Most of these facts aren’t very important in social science computing, but it is important to understand that there ARE different number types, and that they exist for very good reasons. As the domain of social science computing expands, these kinds of distinctions become important to understand.
For example, since the advent of successful speech recognition systems in the 1980s, the branch of linguistics devoted to computer processing of language has undergone a massive expansion and influx of new ideas. Statistical modeling has become much more important. As a result computing the probabilities of very rare linguistics events has become a practical necessity; in such computations, underflow problems often arise, and computational linguists have learned how to write programs that deal with them.
3.3.2. Strings¶
The other basic data type is strings:
>>> X = 'frog'
>>> type(X)
<type 'str'>
When we type in a word with quotes to the Python prompt, or when we write a program that reads in a file of ordinary English text, generally the data type you get is strings. Unless you tell Python otherwise, the data type you get by reading in a file is strings.
Much of this course will be concerned with dealing with string data, since a lot of data of interest to social scientists is in string form.
The important thing to remember about strings is that when you want to explicitly reference a string value, you need quotes b, as in the example above with ‘frog’. Leaving out the quotes is an error:
>>> X = frog
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'frog' is not defined
Python interprets this as a reference to a variable. The variable frog might refer to anything, an integer, a float, a file; Python doesn’t know, and reports an error.
Python allows any character to occur in a string, including the punctiation marks and spaces. So the following is fine:
>>> X = 'The big dog laughed.'
But how about the quotation mark character? Can that occur in a string? The answer is that it can, but you have to wrap the string in a distinct kind of quotation mark. So both of the following are fine:
>>> X = "The big dog laughed and said, 'Hello, Jeremy.'"
>>> Y = 'The big dog laughed and said, "Hello, Jeremy."'
>>> X == Y
False
The convention is that the string expression has to start and end with the same kind of quotation mark. Any quotation marks inside have to be different and are considered part of the strings being referred to, so X and Y differ in that X contains two instances “’” and Y contains two instances of ‘”’. The quotation marks at the beginning and end of the string are not considered part of the string; they are just delimiters, like parentheses in arithmetic, telling you where the first and last character of the string are. So contrast the above examples with the following:
>>> X = "The big dog laughed."
>>> Y = 'The big dog laughed.'
>>> X == Y
True
Which quotation character you use as your delimiter doesn’t matter (as long as there are no quotation characters inside the string).
Generally speaking, strings of more than one line require some special provisions. They should be begun and ended with triple quotes:
>>> X = """
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
"""
>>> print X
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Note that the spaces included at the beginning of each line are part of the string. Such multiline strings serve an important purpose in Python, since they are used for documentation.
Strings can also include special characters such as
tabs. To place a tab in a string use the special \t
symbol; To place a line break in a string use the special
\n symbol. Thus, to place a tab between ‘x’ and ‘y’,
we write:
>>> Z = 'x\ty'
>>> print Z
x y
And since \n produces a line break,
the string X defined above, giving four lines of the Zen of
Python, can also be defined:
>>> X = "\n Beautiful is better than ugly.\n Explicit is better than implicit.\n Simple is better than complex.\n Complex is better than complicated."
>>> print X
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Generally speaking there is little need for multiline strings
with explcit \n, except for strings assembled
from pieces by a program. The triple-quoted form is preferred because
it is more readable.
Footnotes