|
|
|
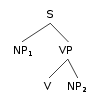
Probabilistic Context Free Grammars |
A probabilistic context free grammar is a context free grammar with probabilities attached to the rules.
|
|||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
Probability Model |
|
|||||||||||||||||||||||||||||||||
|
Estimating Parameters |
Given a tree bank, the maximum likelihood estimate for the PCFG rule:
|
|||||||||||||||||||||||||||||||||
|
Real WSJ data |
python -i print_penn_trees.py penn_example.mrg 0
(Start
(S
(NP (NNP Rolls-Royce) (NNP Motor) (NNPS Cars) (NNP Inc.))
(VP
(VBD said)
(SBAR
(-NONE- 0)
(S
(NP (PRP it))
(VP
(VBZ expects)
(S
(NP (PRP$ its) (NNP U.S.) (NNS sales))
(VP
(cat_TO to)
(VP
(VB remain)
(ADJP (JJ steady))
(PP
(IN at)
(NP (QP (IN about) (CD 1,200)) (NNS cars)))
(PP (IN in) (NP (CD 1990))))))))))
(cat_. .)))
|
|||||||||||||||||||||||||||||||||
|
Real WSJ rules |
Lexical
Below we present a TINY extract of the rule counts from the WSJ corpus. 2 VBZ --> grants 2 VBZ --> grinds 2 VBZ --> gripes 2 VBZ --> groans 2 VBZ --> halts 2 VBZ --> hands 2 VBZ --> harbors 2 VBZ --> hates 2 VBZ --> heats 2 VBZ --> hosts 2 VBZ --> houses 2 VBZ --> ignores 2 VBZ --> industrials 2 VBZ --> irritates 2 VBZ --> jeopardizesPropernames in particular 1 NNP --> JKD 1 NNP --> JPI 1 NNP --> JROE 1 NNP --> JUMPING 1 NNP --> Jaap 1 NNP --> Jacki 1 NNP --> Jaclyn 1 NNP --> Jacobsen 1 NNP --> Jacqueline 1 NNP --> Jacques-Francois 1 NNP --> Jaime 1 NNP --> Jakarta 1 NNP --> Jakes 1 NNP --> Jalaalwalikraam 1 NNP --> Jalalabad 1 NNP --> Jamieson 1 NNP --> Janeiro 1 NNP --> Janice 1 NNP --> Janlori 1 NNP --> Janney 1 NNP --> Jansen 1 NNP --> Jansz. 1 NNP --> Japan-U.SNon-lexical 1 NP --> NNP ''_cat NNP POS 1 NP --> NNP ,_cat 1 NP --> NNP ,_cat CD 1 NP --> NNP ,_cat CD ,_cat CD 1 NP --> NNP ,_cat NNP ,_cat NNP ,_cat NNP ,_cat NNP ,_cat NNP ,_cat NNP CC NNP 1 NP --> NNP ,_cat NNP ,_cat NNP ,_cat NNP ,_cat NNP CC NNP 1 NP --> NNP ,_cat NNP ,_cat NNP NNP CC NNP 1 NP --> NNP ,_cat NNP CC NNP ._cat 1 NP --> NNP ,_cat NNP CC NNP NN NNP NNP 1 NP --> NNP ,_cat NNP CC NNP NNP NNS 1 NP --> NNP ,_cat NNP CC NNPS 1 NP --> NNP ,_cat NNP CC RB NNP 1 NP --> NNP ,_cat NNP NNP ._cat 1 NP --> NNP ,_cat NNP NNP CC NNP NNP 1 NP --> NNP ,_cat NNPS CC NNP NNP 1 NP --> NNP ,_cat RB NN ,_cat 1 NP --> NNP ,_cat RB PRP ,_cat 1 NP --> NNP -LRB-_cat NN -RRB-_cat 1 NP --> NNP -LRB-_cat NNP 1 NP --> NNP -LRB-_cat NNP -RRB-_cat 1 NP --> NNP -LRB-_cat NP -RRB-_cat 1 NP --> NNP ._cat ''_cat NNP 1 NP --> NNP ._cat CC JJ NN NNS |
|||||||||||||||||||||||||||||||||
|
WSJ size |
There are 75347 rules in the part of the wsj corpus conventionally used for training (Sections 2-21). |
|||||||||||||||||||||||||||||||||
|
Rules with probs |
There are 21505 rules with VBZ on the LHS. What is the probability of a VBZ rule with count 2 like the ones we saw above?
VBZ -> grants [0.000093] VBZ --> grinds [0.000093] VBZ --> gripes [0.000093] VBZ --> groans [0.000093] VBZ --> halts [0.000093] VBZ --> hands [0.000093] VBZ --> harbors [0.000093] VBZ --> hates [0.000093] VBZ --> heats [0.000093] VBZ --> hosts [0.000093] VBZ --> houses [0.000093] VBZ --> ignores [0.000093] VBZ --> industrials [0.000093] VBZ --> irritates [0.000093] VBZ --> jeopardizes [0.000093] |
|||||||||||||||||||||||||||||||||
|
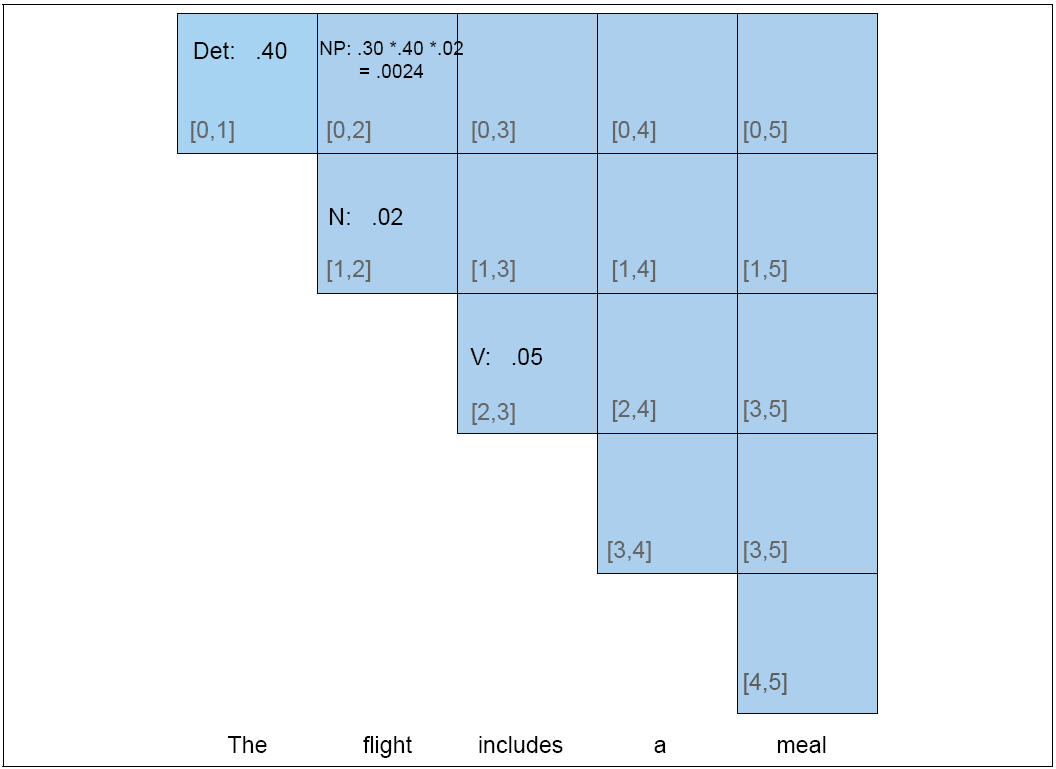
Highest Probability parse |
Our primary subject of interest is finding the highest probability parse for a sentence.
CKY is ideal for our purposes because no constituent spanning (i,j) is built until all ways of building constituents spanning (k,l),
We modify CKY as follows: instead of building a parse table in which each cell assigns value True or False for each category, we build a parse table in which each cell assigns a probability to each category. Each time we find a new way of building an A spanning (i,j), we compute its probability and check to see if it is more propbable than the current value for table[i][j][A].
|
|||||||||||||||||||||||||||||||||
| Example |
Partial PCFG:
|
|||||||||||||||||||||||||||||||||
| Problems |
|
|||||||||||||||||||||||||||||||||
| Independence |
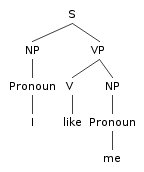
Pronouns (Switchboard corpus [spoken, telephone], Francis et al. 1999)
|
|||||||||||||||||||||||||||||||||
| Lexical |
|
|||||||||||||||||||||||||||||||||
|
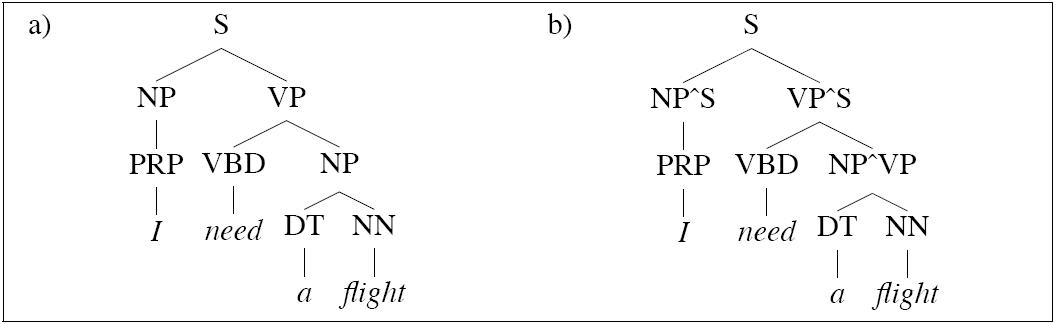
Using grandparents |
Johnson (1998) demonstrates the utility of using the grandparent node as a contextual parameter of a probabilistic parsing model. This option uses more derivational history.
Significant improvement on PCFG:
This strategy is called splitting. We split the category NP in two so as to model distinct internal distributions depending on the external context of an NP Note that in the work above, preterminals are not split. |
|||||||||||||||||||||||||||||||||
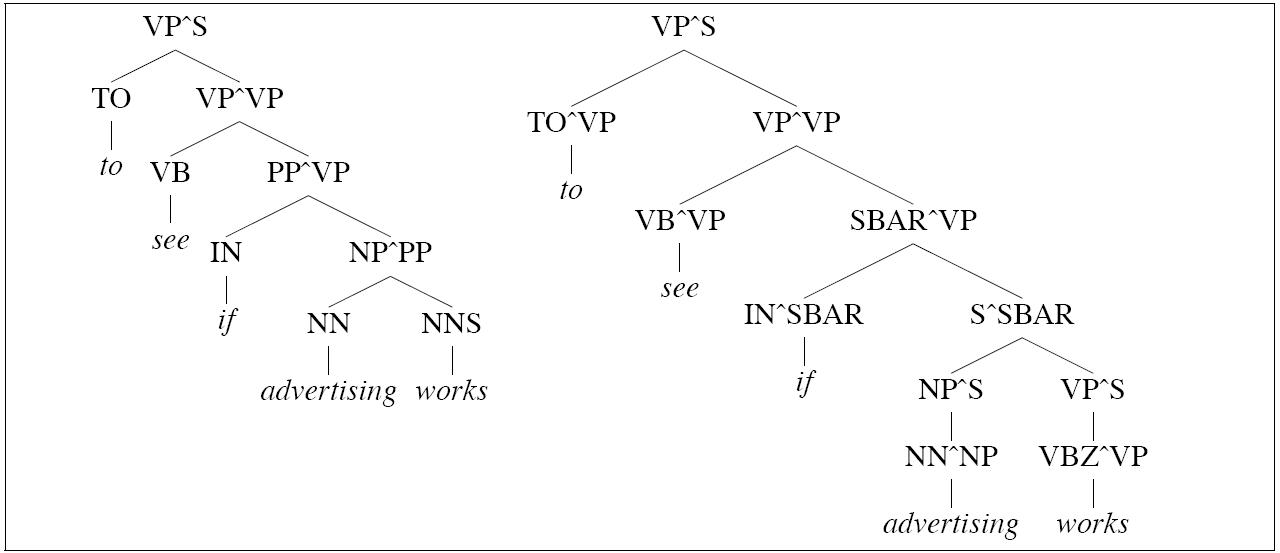
| Splitting preterminals |
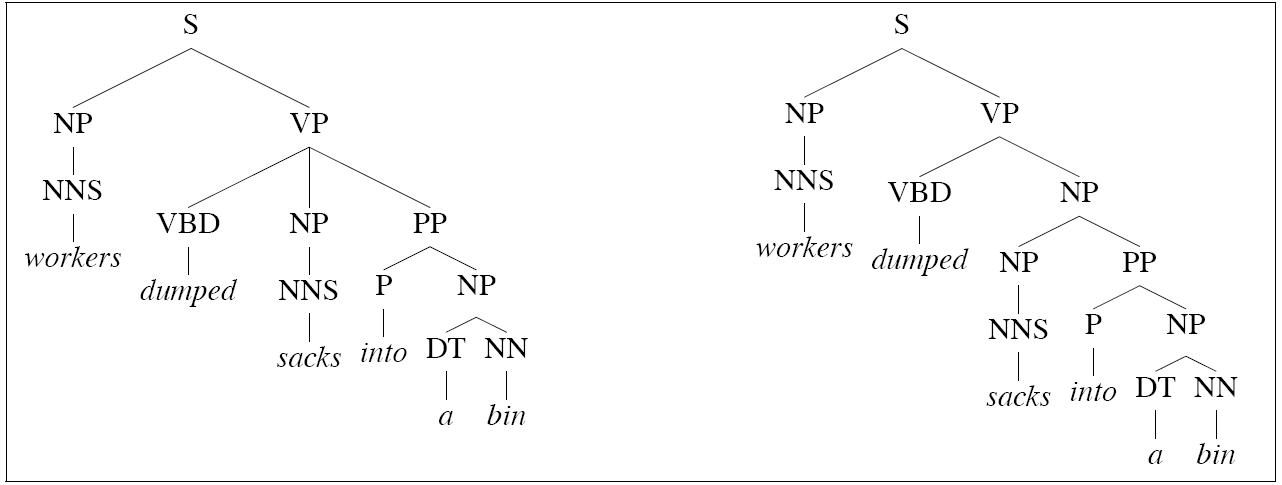
Johnson's grandparent grammars work because they reclaim some of the ground lost due to the incorrectness of the independence assumptions of PCFGs. But the other problem for PCFGs that we noted is that they miss lexical dependencies. If we extend the idea of gradparent information to preterminals, we can begin to capture some of that information.
The parse on the left is incorrect because of an incorrect choice between the following two rules:
PP → IN SBAR The choice is made possible because the string advertising works can be analyzed either as an SBAR or an NP:
|
|||||||||||||||||||||||||||||||||
|
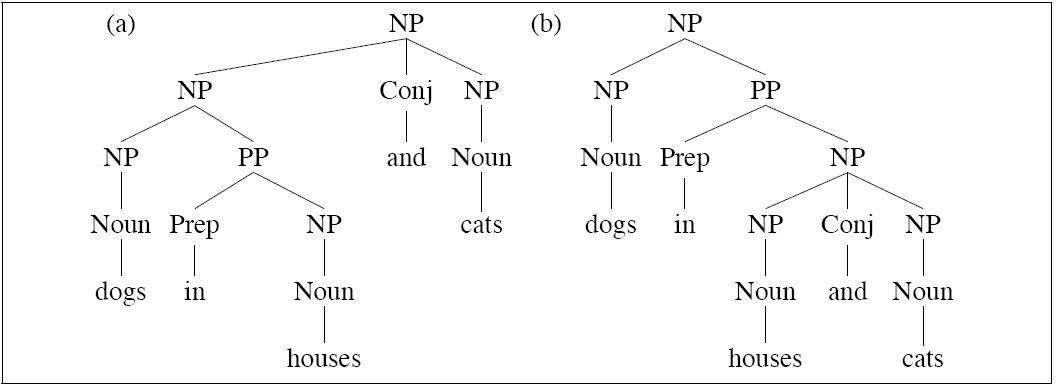
Generalized Splitting |
Obviously there are many cases where splitting helps. But there are also cases where splitting hurts. We already have a sparseness problem. If a split results in a defective or under-represented distribution, it can lead to overfitting and it can hurt. Generalizations that were there before the split can be blurred or lost. Two approaches: |
|||||||||||||||||||||||||||||||||
|
Lexicalized CFGs |
An extreme form of splitting:
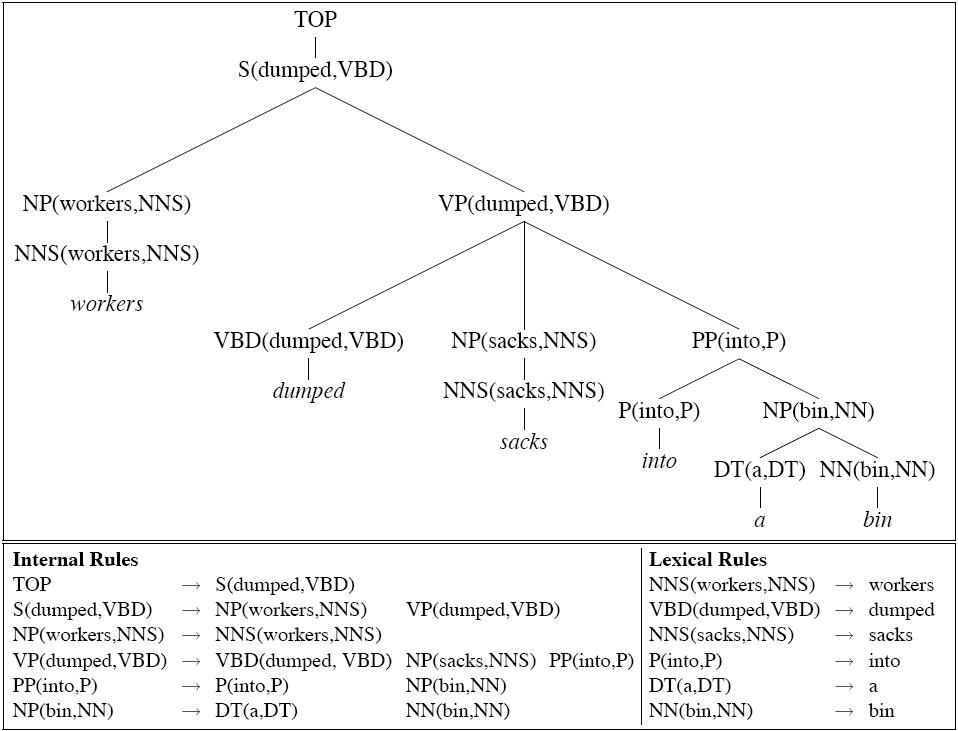
Lexical rules all have probability 1.0 |
|||||||||||||||||||||||||||||||||
|
Sparseness problems |
Maximum likelihood estimates for the PCFG defined by lexicalized splitting are doomed by sparseness: The rule prob for:
is:
How do we usually solve sparseness problems? We need to make some further independence assumptions! |
|||||||||||||||||||||||||||||||||
| Collins I |
Generation story: Break down a rule into number of contextually dependent subevents which collectively "generate" an occurrence of a rule:
Basic decomposition: Generate head first, then Li modifers terminating with STOP, then Ri modifiers terminating with STOP. For the tree above we have the following sub event probs
Pr(PP(into,P) | VP(dumped,VBD),VBD(dumped,VBD)) × Pr(STOP | VP(dumped,VBD), VBD(dumped,VBD),PP) |
|||||||||||||||||||||||||||||||||
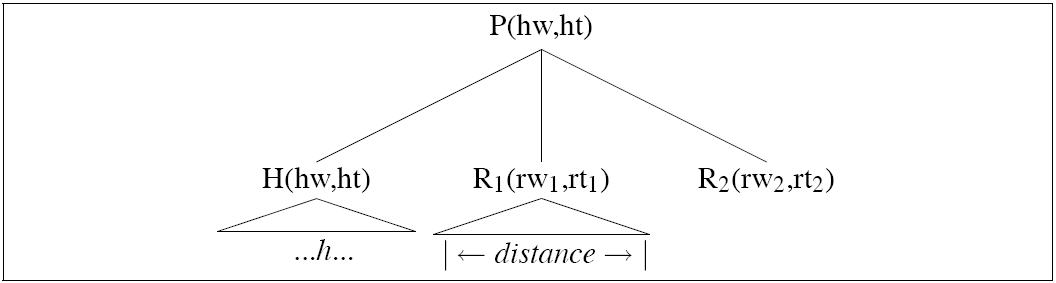
| Distance |
Collins discovered that adding distance of modifier from head (measured as number of intervening words) is a useful measure:
|
|||||||||||||||||||||||||||||||||
|
Collins Backoff |
The three models are linearly interpolated. |
|||||||||||||||||||||||||||||||||
| State of the art |
Using the PARSEVAL metric for comparing gold standard and system parse trees (Black et al. 1991), state-of-the-art statistical parsers trained on the Wall Stree Journal treebank are performing at about 90% precision 90% recall. |