7.6. Text classification¶
In this section we take a practical look at text classification using some scikit learn tools.
7.6.1. Getting the data¶
To follow along with this section
you need to have some NLTK movie reviews data
installed. First make sure you have nltk installed as a Python module
(or the first line in the code block below won’t work). Then install the
data as follows:
import nltk
nltk.download('movie_reviews')
This will install the movie reviews data on your machine (or on your virtual machine if you are working a Cloud environment like Google Colab), after which all the code in this section should work.
7.6.2. Peliminaries: Code for getting data and extracting features¶
import nltk
nltk.download()
showing info http://www.nltk.org/nltk_data/
True
def unigram_features (words):
"""
This is the simplest possible feature representation of a document.
Each word is a feature.
"""
return dict((word, True) for word in words)
def extract_features (corpus, file_ids, cls, feature_extractor=unigram_features):
"""
Turn a set of files all belonging to one class into a list
of (feature dictionary, cls) pairs, to be used in testing or training
a classifier.
"""
return [(feature_extractor(corpus.words(i)), cls) for i in file_ids]
def get_words_from_corpus (corpus, file_ids):
for file_id in file_ids:
words = corpus.words(file_id)
for word in words:
yield word
7.6.3. Loading the data¶
In line 3 of the next cell, we import Bo Pang and Lillian Lee’s movie reviews corpus from NLTK [PANGLEE2004]. The commented out code in Line 5 prints some information about the corpus properties, if you’d like to know more.
# Using a corpus of movie review data
# 2000 positive and negative reviews, evenly balanced.
from nltk.corpus import movie_reviews as mr
# If you want to read the corpus collectors' introduction to
# this corpus, uncomment the next line.
#print mr.readme()
The movie review data is packaged up as an NLTK corpus, which gives us access to a number of tools for text handling. The simplest is that we have two views of the movie review data, word by word and character by character.
The character by character view uses the raw method, which returns
all the data with no argument, or just the data from a single file with a
fileid argument:
data = dict(pos = mr.fileids('pos'),
neg = mr.fileids('neg'))
print mr.raw(data['pos'][0])[:100]
films adapted from comic books have had plenty of success , whether they're about superheroes ( batm
The word by word character view uses the words method:
.. code:: python
print mr.words(data[‘pos’][0])[:10]
[u'films', u'adapted', u'from', u'comic', u'books', u'have', u'had', u'plenty', u'of', u'success']
We will be using the word by word view.
7.6.4. Training a classifier¶
Here is some code for training a classifier.
from nltk.corpus import movie_reviews as mr
# Use a Naive Bayes Classifier
from nltk.classify import NaiveBayesClassifier
data = dict(pos = mr.fileids('pos'),
neg = mr.fileids('neg'))
#######################################################################
#
# Dividing up the data
#######################################################################
# Use 90% of the data for training
test_start_index = 900
neg_training = extract_features(mr, data['neg'][:test_start_index], 'neg',
feature_extractor=unigram_features)
# Use 10% for testing the classifier on unseen data.
neg_test = extract_features(mr, data['neg'][test_start_index:], 'neg',
feature_extractor=unigram_features)
pos_training = extract_features(mr, data['pos'][:test_start_index],'pos',
feature_extractor=unigram_features)
pos_test = extract_features(mr, data['pos'][test_start_index:],'pos',
feature_extractor=unigram_features)
train_set = pos_training + neg_training
test_set = pos_test + neg_test
Line 2 imports the Classifier, and lines 4 and 5 store the two halves
of the corpus in a dictionary (positive and negative reviews, 1000 of
each). The next commands extract features from the data files, sorting
them in pos and negative training and positive and negative test
sets. The training set is 90% of the the data; the test set is 10% of
the data. The feature extractor used is unigram_features, the
simple feature extractor defined in the first code cell of this
notebook. This feature extractor just uses every word that appears in
a document as a feature. Finally in line 31 the positive and negative
training data is combined into a single training set, and in line 36,
a Naive Bayes (NB) classifier is trained.
We have now split the data into two unequal haves, each with positive
and negative examples, and called the larger half train_set and the
smaller half test_set.
Next we train the classifier using the Naive Bayes classifier that comes prepackaged with NLTK.
# Train a classifier on our training data.
classifier = NaiveBayesClassifier.train(train_set)
7.6.5. A demonstration¶
In the next code cell, we demonstrate what the classifier does on the first reviews in the the positive and negative training set. The output window shows that both reviews are correctly classified by the NB classifier we just trained.
First, we pick a review.
def get_review_text (clf,file_id,start=0,end=None):
words = list(mr.words(data[clf][file_id]))
return ' '.join(words[start:end])
print get_review_text('pos',0,end=95)
print ' . . . . . . '
print get_review_text('pos',0,start=-190)
films adapted from comic books have had plenty of success , whether they ' re about superheroes ( batman , superman , spawn ) , or geared toward kids ( casper ) or the arthouse crowd ( ghost world ) , but there ' s never really been a comic book like from hell before . for starters , it was created by alan moore ( and eddie campbell ) , who brought the medium to a whole new level in the mid ' 80s with a 12 - part series called the watchmen .
. . . . . .
, but cinematographer peter deming ( don ' t say a word ) ably captures the dreariness of victorian - era london and helped make the flashy killing scenes remind me of the crazy flashbacks in twin peaks , even though the violence in the film pales in comparison to that in the black - and - white comic . oscar winner martin childs ' ( shakespeare in love ) production design turns the original prague surroundings into one creepy place . even the acting in from hell is solid , with the dreamy depp turning in a typically strong performance and deftly handling a british accent . ians holm ( joe gould ' s secret ) and richardson ( 102 dalmatians ) log in great supporting roles , but the big surprise here is graham . i cringed the first time she opened her mouth , imagining her attempt at an irish accent , but it actually wasn ' t half bad . the film , however , is all good . 2 : 00 - r for strong violence / gore , sexuality , language and drug content
Reading this makes it clear why movie reviews are hard, especially with the approach we’re taking; each word is treated as an independent feature whose presence increases or decreases the probability the review is positive. Overall it’s positive review but it’s not easy finding single words that might give us good evidence of that, and there are words that probably point the other way as well:
Pos Neg
-----------------
ably dreariness
flashy violence
surprise bad
strong creepy
deftly cringed
good
oscar
winner
great
Nevertheless, let’s trry this out and see how we do.
predicted_label0 = classifier.classify(pos_test[0][0])
print 'Predicted: %s Actual: pos' % (predicted_label0,)
Predicted: pos Actual: pos
We got it right! Let’s try a negative review.
print get_review_text('neg',0,end=120)
print ' . . . . . . '
print get_review_text('neg',0,start=-180)
plot : two teen couples go to a church party , drink and then drive . they get into an accident . one of the guys dies , but his girlfriend continues to see him in her life , and has nightmares . what ' s the deal ? watch the movie and " sorta " find out . . . critique : a mind - fuck movie for the teen generation that touches on a very cool idea , but presents it in a very bad package . which is what makes this review an even harder one to write , since i generally applaud films which attempt to break the mold , mess with your head and such
. . . . . .
it ' s confusing , it rarely excites and it feels pretty redundant for most of its runtime , despite a pretty cool ending and explanation to all of the craziness that came before it . oh , and by the way , this is not a horror or teen slasher flick . . . it ' s just packaged to look that way because someone is apparently assuming that the genre is still hot with the kids . it also wrapped production two years ago and has been sitting on the shelves ever since . whatever . . . skip it ! where ' s joblo coming from ? a nightmare of elm street 3 ( 7 / 10 ) - blair witch 2 ( 7 / 10 ) - the crow ( 9 / 10 ) - the crow : salvation ( 4 / 10 ) - lost highway ( 10 / 10 ) - memento ( 10 / 10 ) - the others ( 9 / 10 ) - stir of echoes ( 8 / 10 )
Again, conflicting word cues:
Pos Neg
-----------------
cool nightmares
applaud fuck
surprise bad
excites rarely
hot horror
Let’s see how we do.
predicted_label1 = classifier.classify(neg_test[0][0])
print 'Predicted: %s Actual: neg' % (predicted_label1,)
# To see the the feature dictionary passed in to the classifier,
# uncomment the next line
#pos_test[0][0]
Predicted: neg Actual: neg
Right again!
Let’s try the examples we cooked up before. We need go to from a string
like "Inception is the best movie ever" to a feature dictionary and
pass that to the classifier.
classifier.classify(unigram_features('Inception is the best movie ever'.split()))
'pos'
classifier.classify(unigram_features("I don't know how anyone could sit through Inception".split()))
'neg'
Interesting. We may get some insight on this one below.
7.6.6. Most informative features¶
Heres what our classifier learned. These are the features for which the ratio of the positive to negative probability (or vice versa) is the highest.
classifier.show_most_informative_features()
Most Informative Features
outstanding = True pos : neg = 15.6 : 1.0
ludicrous = True neg : pos = 14.2 : 1.0
astounding = True pos : neg = 12.3 : 1.0
avoids = True pos : neg = 12.3 : 1.0
idiotic = True neg : pos = 11.8 : 1.0
atrocious = True neg : pos = 11.7 : 1.0
fascination = True pos : neg = 11.0 : 1.0
offbeat = True pos : neg = 11.0 : 1.0
animators = True pos : neg = 10.3 : 1.0
symbol = True pos : neg = 10.3 : 1.0
We have more features showing up as good indicators of positive, and this is a fairly good indicate or a probl;em with our classifier, as we’ll see below. Actually the classifier is a little too reluctant to classify reviews as negative on the test set. This suggests that reliable negative indicators are not that common, at least on the test set.
7.6.7. Serious testing¶
The next cell takes the first step toward testing a classifier a little
more seriously. It defines some code for evaluating classifier output.
The evaluation metrics defined are precision, recall, and accuracy. Let
N be the size of the dataset, 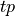 and
and 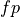 be true and
false positive respectively and
be true and
false positive respectively and 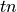 and
and 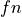 be true and
false negatives respective. Accuracy is the percentage of correct
answers out of the total corpus
be true and
false negatives respective. Accuracy is the percentage of correct
answers out of the total corpus 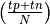 ,
Precision is the percentage of true positives out all positive guesses
the system made
,
Precision is the percentage of true positives out all positive guesses
the system made 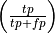 , while recall is
the percentage of true positives out of all good reviews
, while recall is
the percentage of true positives out of all good reviews
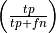 .
.
from sklearn.metrics import precision_score, recall_score,accuracy_score
def do_evaluation (pairs, pos_label='pos', verbose=True):
predicted, actual = zip(*pairs)
(precision, recall,accuracy) = (precision_score(actual,predicted,pos_label=pos_label),
recall_score(actual,predicted,pos_label=pos_label),
accuracy_score(actual,predicted))
if verbose:
print_results(precision, recall, accuracy, pos_label)
return (precision, recall,accuracy)
def print_results (precision, recall, accuracy, pos_label):
banner = 'Evaluation with pos label = %s' % pos_label
print
print banner
print '=' * len(banner)
print '{0:10s} {1:.1f}'.format('Precision',precision*100)
print '{0:10s} {1:.1f}'.format('Recall',recall*100)
print '{0:10s} {1:.1f}'.format('Accuracy',accuracy*100)
The code in the next cell actually tests our NB classifier on the entire
test set and prints out the result. Note that precision and recall give
different results depending on which class we think of ourselves as
detecting (which class we think of as positive). We give evaluation
numbers with respect to positive and negative reviews. These show that
our classifier actually misses a number of negative reviews because it
misclassifies them as positive (recall of positive high, recall of
negative low). Thus its high recall number when pos_cls = pos needs
to be taken with a grain of salt. It achieves this high recall by
guessing positive a lot of the time. In fact, it guesses positive 74% of
the time, even though it was trained on data that was 50% positive and
50% negative.
This fact make it even more interesting that we correctly classified
I don't know how anyone could sit through Inception.
as negative. In fact it turns out ‘sit’ is just a pretty good indicator of a negative review. It occurs 79 times in our set of 1000 negative reviews, quite often followed by ‘through’. This tells us something important. Our intuitions aren’t always good at finding good features.
So why does our classifier guess positive so often. Well, probably because it had more success finding striong positive indicators than it did finding strong negative indicators, as our glance at the most informative features suggested. This is something we might want to worry about as we design good classifiers.
pairs = [(classifier.classify(example), actual)
for (example, actual) in test_set]
do_evaluation (pairs)
pos_guesses = [p for (p,a) in pairs if p=='pos']
pos_actual = [a for (p,a) in pairs if a=='pos']
do_evaluation (pairs, pos_label='neg')
print 'Note that {:.1%} of our classifier guesses were positive'.format(float(len(pos_guesses))/len(pairs))
print 'While {:.1%} of the reviews were actually positive'.format(float(len(pos_actual))/len(pairs))
# to see the actual pairs that came out of the test uncomment the next line
#pairs
Evaluation with pos label = pos
===============================
Precision 65.5
Recall 97.0
Accuracy 73.0
Evaluation with pos label = neg
===============================
Precision 94.2
Recall 49.0
Accuracy 73.0
Note that 74.0% of our classifier guesses were positive
While 50.0% of the reviews were actually positive
7.6.8. SVM Classifier¶
We’ll also try a Support Vector Machine classifier on the movie review data, both to illustrate a different learning model and to illustrate a somewhat different set of machine learning tools than those in NLTK.
Since we’re not taking advantage of NLTK’s code for handling its own data this time, the script below is a little closer to what you would actually end up doing with “raw” labeled data that you had downloaded from the web or some other data source. It still skips an important step called Tokenization which we defer for now, because this data has already been tokenized.
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.svm import LinearSVC
import os.path
def add_data_from_files (file_list,data_list):
for f in file_list:
with open(f,'r') as fh:
data_list.append(fh.read())
home = os.getenv('HOME')
# This is where MY NLTK data is. Yours should be in a similar place relative
# to what your machine thinks is HOME.
data_dir = os.path.join(home,'nltk_data/corpora/movie_reviews/')
clses = ['pos','neg']
# The data is in the data_dir, sorted into subdirectories, one for each class.
data_dirs = [os.path.join(data_dir,cls) for cls in clses]
# We use a somewhat more traditional feature weights, called TFIDF weights
vectorizer = TfidfVectorizer(sublinear_tf=True, max_df=0.5,
stop_words='english')
# We're going to compute 4 lists training data and labels, test data a nd labels
train_labels = []
test_labels = []
train_data = []
test_data = []
training_proportion = (9,10)
for i,cls in enumerate(clses):
d_dir = data_dirs[i]
os.chdir(d_dir)
cls_files = os.listdir(d_dir)
num_cls_files = len(cls_files)
training_index = round((training_proportion[0] *(num_cls_files/training_proportion[1])))
train_labels.extend(cls for f in cls_files[:training_index])
test_labels.extend(cls for f in cls_files[training_index:])
add_data_from_files (cls_files[:training_index],train_data)
add_data_from_files (cls_files[training_index:],test_data)
# Now with data set represented as a list of strings (one from each file),
# extract the TFIDF features
train_features = vectorizer.fit_transform(train_data)
# We extract features from the test data using the same vectorizer
# trained on training data. The TFIDF feature model has been fit to
# (depends only on) the training data.
test_features = vectorizer.transform(test_data)
# Create an SVM classifier instance
clf = LinearSVC(loss='squared_hinge', penalty="l2",
dual=False, tol=1e-3)
# Train (or "fit") the model to the training data.
clf.fit(train_features, train_labels)
# Test the model on the test data.
predicted_labels = clf.predict(test_features)
# Evaluate the results
pos_guesses = [p for p in predicted_labels if p=='pos']
pos_actual = [p for p in test_labels if p=='pos']
print 'Note that {:.1%} of our classifier guesses were positive'.format(float(len(pos_guesses))/len(test_labels))
print 'While {:.1%} of the reviews were actually positive'.format(float(len(pos_actual))/len(test_labels))
do_evaluation (zip(predicted_labels,test_labels), pos_label='pos', verbose=True)
do_evaluation (zip(predicted_labels,test_labels), pos_label= 'neg', verbose=True)
Note that 48.5% of our classifier guesses were positive
While 50.0% of the reviews were actually positive
Evaluation with pos label = pos
===============================
Precision 90.7
Recall 88.0
Accuracy 89.5
Evaluation with pos label = neg
===============================
Precision 88.3
Recall 91.0
Accuracy 89.5
(0.88349514563106801, 0.91000000000000003, 0.89500000000000002)
Notice our positive label recall actually went down a bit, but as the accuracy shows, it’s a much better classifier. The average of precision and recall is much higher. And notice the percentage of positive guesses is much closer to the actual percentage in the data.