2.3. Why Python?¶
2.3.1. High level reasons¶
It is a general purpose programming language. The problem with learning how to use a more special-purpose tool is that effort expended in learning how to solve particular kinds of problems doesn’t extend well to other kinds of problems. Effort expended learning Python gives you access to a wide variety of data processing and data analysis tools.
It is a high-level language. This means it takes care of many of the details you have to worry about in other languages for you. It also means if you can break the solution to a problem down into simple steps, there is probably a natural way to express those steps in Python. More simply put, Python can be useful in a variety of contexts and useful Python programs can be very short.
It is used by a large activity community, including researchers in science and social science. Help is available. The problems you encounter are likely to have already been solved.
It is also taught in many university courses, as well in industry (Google Python course), both inside and outside computer science departments. This makes collaboration easier.
There are a lot of teaching resources, and not just because of (4). The Python community (for a variety of reasons) has taken the problem of teaching the language seriously.
Writing a readable program is one of the best ways to track precisely what you have done with your data to get your results. A clear path from the raw data to the results is one of the best ways to analyze problems with your results and develop new questions. Python makes it easy to write clear programs.
2.3.2. Practical reasons¶
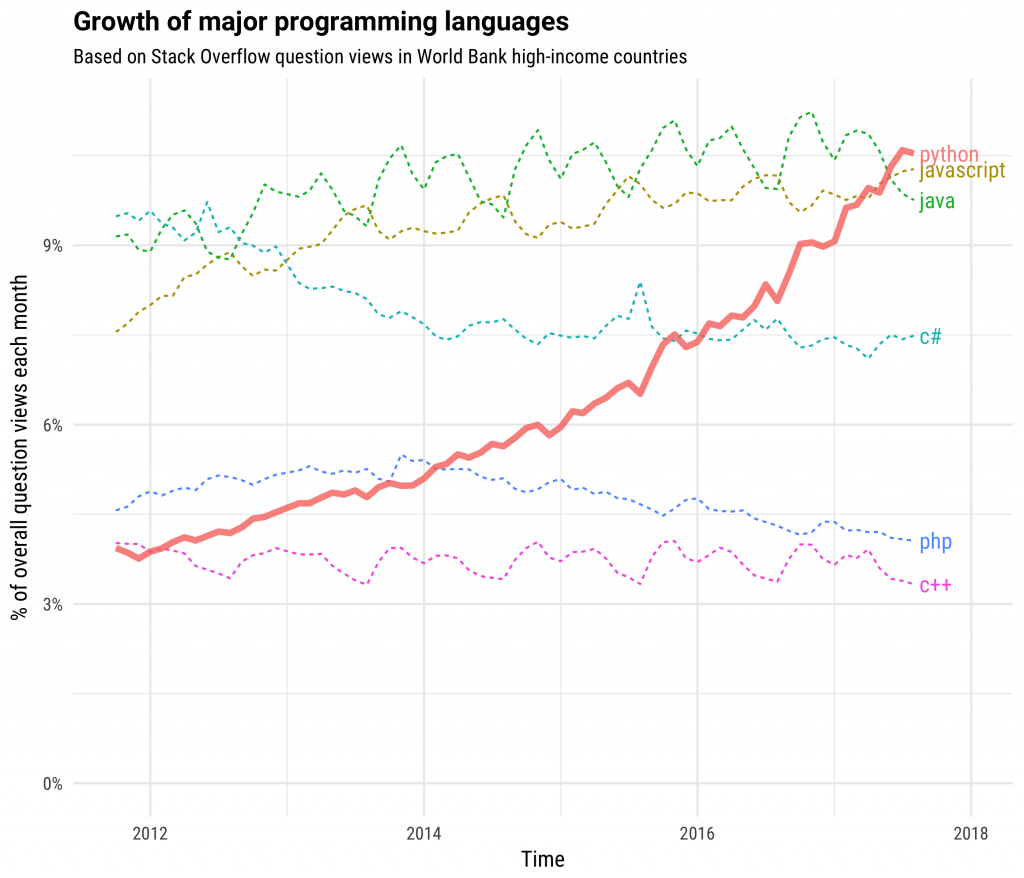
The first practical reason to hop on board the Python bandwagon is that it is a bandwagon. Popularity is usually a shallow reason for liking something, but in the case of a programming languages, it means an active community of developers; and since most programming problems have already been solved, an active community means a large and growing supply of solutions. All this before saying one word about efficiency, versatility, ease of use, and learnability. This graph, published in stackoverflow, shows the growth in question views on Stackoverflow in high-income countries for six programming languages. This number, while an indirect indicator, is a reasonable indicator of the number of programmers new to the language. The time period is 2012–2018:
Continuing this theme, we have tghe following Quora post.
2.3.3. Python’s use in industry¶
This section is an exerpt from an article on the Real Python site. Material has been excerpted for only 4 of the 8 companieas discussed there.
Source: Real Python: 8 World class companies that use Python
In the beginning, the founders of Google made the decision of “Python where we can, C++ where we must.” This meant that C++ was used where memory control was imperative and low latency was desired. In the other facets, Python enabled for ease of maintenance and relatively fast delivery.
Even when other scripts were written for Google in Perl or Bash, these were often recoded into Python. The reason was because of the ease of deployment and how simple Python is to maintain. In fact, according to Steven Levy – author of In the Plex, Google’s very first web-crawling spider was first written in Java 1.0 and was so difficult that they rewrote it into Python.
Python is now one of the official Google server-side languages—C++, Java, and Go are the other three—that are allowed to be deployed to production.
Peter Norvig:
Python has been an important part of Google since the beginning, and remains so as the system grows and evolves. Today dozens of Google engineers use Python, and we’re looking for more people with skills in this language.
Quora
According to Adam D’Angelo, Quora decided not to go with C# because it’s a proprietary Microsoft language and they didn’t want to be beholden to any future changes put out. Additionally, any open source code had second-class support at best.
Java was more painful to write in than Python and it didn’t play as nicely with non-Java programs as Python did. At the time, Java was also in its infancy, so they were worried about future support and if the language would continue to grow.
Instead, the founders of Quora took their lead from Google, choosing to use Python where they could because of its ease of writing and readability, and implemented C++ for the performance critical sections. They got around Python’s lack of typechecking by writing unit tests that accomplish much the same thing.
Another key consideration for using Python was the existence of several good [web] frameworks at the time including Django and Pylons. Additionally, because they knew that Quora was going to involve server/client interactions that wouldn’t necessarily be full page loads, having Python and JS play so well together was a huge plus.
Netflix
Netflix uses Python in a very similar manner to Spotify, relying on the language to power its data analysis on the server side. It doesn’t just stop there, however. Netflix allows their software engineers to choose what language to code in, and have noticed a large upsurge in the number of Python applications.
When surveyed, Netflix engineers cite the standard library, the extremely active development community, and the rich variety of third party libraries available to solve nearly any given problem. Additionally, because Python is so easy to develop, it has become a linchpin in many of Netflix’s other services.
Reddit had 542 million visitors every month throughout 2017, making it the fourth most visited website in the United States and seventh most visited in the world. In 2015, there were 73.15 million submissions and 82.54 billion pageviews. And behind it all, forming the software backbone, was Python.
Reddit was originally coded in Lisp, but in December of 2005, six months after its launch, the site was recoded into Python. The primary reason for the change was that Python had a wider range of code libraries and was more developmentally flexible.
2.3.4. A summary of the reasons¶
Gathering together a hodge podge of social and technical reasons, here’s what we get.
Free
Stable
Portable across many platforms
Mature
Lots of applications of many types
Lots of solid programming libraries
Programs working on many platforms (Windows, Unix, MacOS)
Portability claims tested
Good for beginners
Good for rapid prototyping
Easy access to documentation
Extensions
C
C++
Java
Fortran
Everything is an object, good for debugging, goes back to good for rapid prototyping.
2.3.5. Data Science¶
Today, the most popular alternatives to Python for data scientists are R, Matlab/Octave, and Mathematica/Sage. Python is becoming a more and more popular choice, in part because it has imported or adapted some of the tools available in these competing languages. In answer to the question, ‘Why is Python the language of choice for data scientists?’, Wes McKinney, author of Python for Data Analysis, basically gave a list of good ideas that had been implemented in Python, some imported from other languages. The following list is adapted from his, which appeared in a recent Quora post:
The Python community invested in the mid-1990s in an “extension to Python to support numeric analysis as naturally as Matlab does.” This evolved into
NumPy. Support for Matlab-like array manipulation is a major reason to prefer Python over Perl and Ruby.Built on top of
numpy, thescipylibrary provides variety of statistical and scientific computing tools.The plotting functionality of Matlab was ported to Python with
matplotlib. Support for Matlab-like plotting is another advantage Python has over Perl and Ruby.From R, the data frame and associated manipulations have been implemented in the Python library
pandas.The
scikit-learnproject has implemented ansklearnmodule in Python which provides a common interface to many machine learning algorithms, similar to the caret package in R.From Mathematica/Sage, the concept of a “notebook” has been implemented with IPython notebooks.
In this course, you will be introduced to all the libraries McKinnon mentions above, NumPy, sklearn, numpy, scipy, and pandas. We will make heavy use of Python notebooks, both Jupyter Notebooks
and Google Colab notebooks, whose frontends share a lot of features.
In addition to those well-established modules we will also have a look at some relative newcomers, including a Python module for Deep Learning (Pytorch), Regular expressions (re), and network analysis and manipulation, the latter of particular use in analyzing social networks.
McKinnon (wisely) also mentions some of Python’s deficiencies.
A more cumbersome syntax for array manipulations and formula specification. The Matlab/Octave syntax for array manipulation is still preferred (that’s why it’s used in the Stanford Machine Learning (ML) class, for example), and the R syntax for formula specification is quite nice.
Lack of a Python equivalent to R’s
ggplot2for static graphics and Javascript’s D3 for interactive graphics. Thematplotliblibrary is hard to install, hard to use, and does not facilitate building interactive graphics for the web. [We are going to usematplotlibin this course. Recognizing that McKinney is right, we will relieve you of the burden of installation by a using a prepackaged Python distribution. Thehard to usepart is right, to some extent, but the issues have been ameliorated with some addon plotting facilities we will learn about.]The scalability limits of NumPy and pandas when working with large data sets. Again, more recent versions of Python have ameliorated these problems. There’s quite a bit that can be done with Numpy and pandas in their current forms.
The lack of an embedded, declarative language for data manipulation, similar to the LINQ project. Pandas is useful as a low-level data manipulation toolkit, but tracking down the custom Pandas syntax for complex operations can be frustrating. This is only somewhat true. The pandas documentation has improved and there os considerable consistency in the command syntax. We will cover some of that.
The lack of an IDE of similar quality to R Studio. This is not an issue for us. The notebook interfaces are quite powerful and will provide the scaffolding for analyses of considerable sophistication. At a certain point in the process of completing a large, nuts and bolts programming project, notebooks are no longer the tool of choice. But notebooks can take you a long way down, the road and they are sufficient for many kinds of data analysis, our main goal here.
2.3.6. What about statistics?¶
Since the class is about using Python primarily in a data analysis and data collection context, the question arises: what about doing statistical analysis? Is Python the right tool? I will try to answer this question by focusing on the most popular open source statistical tool package, R. But the points made below probably apply equally well to any mature statistical package, such as SAS.
I found the following stackexchange.com post by an Austin data scientist name Ben Dundee quite on point. It accurately describes some of the tradeoffs, and touches on some points that are quite general.
Background: I’m a data scientist at a startup in Austin, and I come from grad school (Physics). I use Python day-to-day for data analysis, but use R a bit. I also use C#/.NET and Java (just about daily), I used C++ heavily in grad school.
I think the main problem with using Python for numerics (over R) is the size of the user community. Since the language has been around for ever, lots of people have done things that you’re likely to want to do. This means that, when faced with a hard problem, you can just download the package and get to work. And R “just works”: you give it a dataset, and it knows what summary statistics are useful. You give it some results, and it knows what plots you want. All the common plots you’d want to make are there, even some pretty esoteric ones that you’ll have to look up on Wikipedia. As nice as scipy/numpy/pandas/statsmodels/etc. are for Python, they’re not at the level of the R standard library.
The main advantage of Python over R is that it’s a real programming language in the C family. It scales easily, so it’s conceivable that anything you have in your sandbox can be used in production. Python has Object Orientation baked in, as opposed to R where it feels like kind of an afterthought (because it is). There’s other stuff that Python does nicely too: threading and parallel processing are pretty easy, and I’m not sure if that’s the case in R. And learning Python gives you a powerful scripting tool, too. ….
I’ll add this as a bit of a kicker: since you’re still in school, you should think about jobs. You’ll find more job postings for highly skilled Python devs than you will for highly skilled R devs. In Austin, jobs for Django devs are kind of falling out of the sky. If you know R really well, there are a few places where you’ll be able to capitalize that skill (Revolution Analytics, for example), but lots of shops seem to use Python. Even in the field of data analysis/data science, more people seem to be turning to Python.
And don’t underestimate that you may work with/for people who only know (say) Java. Those people will be able to read your Python code pretty easily. This won’t necessarily be the case if you do all of your work in R. (This comes from experience.)
Finally, this may sound superficial, but I think the Python documentation and naming conventions (which are religiously adhered to, it turns out) is a lot nicer than the utilitarian R doc. This will be hotly debated, I’m sure, but the emphasis in Python is readability. That means that arguments to Python functions have names that you can read, and that mean something. In R, argument names are often truncated—I’ve found this less true in Python. This may sound pedantic, but it drives me nuts to write things like ‘xlab’ when you could just as easily name an argument ‘x_label’ (just one example)—this has a huge effect when you’re trying to learn a new module/package API. Reading R doc is like reading Linux man pages—if that’s what floats your boat, then more power to you. When I have a question about how something works in R, I avoid the R documentation, whereas I START with the Python doc when I’m confused about Python.
All of that being said, I’d suggest the following (which is also my typical workflow): since you know Python, use that as your first tool. When you find Python lacking, learn enough R to do what you want, and then either:
Write scripts in R and run them from Python using the subprocess module, or Install the RPy module.
Use Python for what Python is good at and fill in the gaps with one of the above. This is my normal workflow—I usually use R for plotting things, and Python for the heavy lifting.
So to sum up: because of Python’s emphasis on readability (search google for “Pythonic”), the availability of good, free IDEs, the fact that it’s in the C family of languages, the greater possibility that you’ll be able to capitalize the skillset, and the all-around better documentation-style of the language, I’d suggest making Python your go-to, and relying on R only when necessary.
The takeaway here is that Python is not a replacement for a mature statistics package like R. For many data analysis problems, you will find the measures you want packaged up with intelligence and care in R, and even where a comparable solution might be available in Python, it may be more work to squeeze out exactly what you want. Python, on the other hand, is a better all-purpose programming language; it’s easier to learn; and the code is more readable.
A point Dundee does not make but which is important, is that
moving between R and Python is made much easier because of
Python packages like pandas, mentioned by McKinney above,
which provide data structures
like data frames, which are virtually identical to R
data frames.
2.3.7. The Appropriateness Principle¶
The discussion about R makes clear a point that will be important throughout. Python is not good at everything.
The basic justification for Python is that it is readable and good at many things, and that it is good at combining the results of other programs. Thus it is an excellent choice as the toplevel language of a large data analysis project, and may also be the right choice for many of the modules of that project. But it is not always the right choice.
As the discussion of R shows, Python has shortcoming as a statistical analysis tool. Another area where Python has shortcomings is visualization. Later in this course, we will recommend an R program for visualizing word clouds, and we will recommend a Java program (Gephi) for visualization of large graphs.
So the operational principle is the Appropriateness Principle.
Always use Python for the things it can do. Never use Python for the things it can’t do.
2.3.8. Examples¶
Have a look here For a nice set of examples of the readability/simplicity of Python. This illustrates in a fairly concrete way why Python is a good programming language for beginners.
2.3.9. Further reading¶
John Shipman’s very helpful Quick Reference (not for beginners)
Guido van Rossum and Dave Goodger on documentation conventions
Peter Norvig’s excellent Python/Lisp comparison (not for beginners, but fairly useful even if you don’t know a thing about Lisp)
David Goodger’s “Code like a Pythonista” page (also not for beginners, but very readable).